2023.5.29 增加Riffusion,MusicLM。
2022.11.30 更新一篇综述推荐。
2020.5.1 更新文章,添加OpenAI的jukebox模型和demo链接。
被导师看到了这个回答,捂脸,班门弄斧的感觉……
另外说一个题外话。评论区一些知友似乎很关心“人工智能能不能理解情感并正确表达出来”。这方面其实有一个子领域在努力,叫做“音乐情感检索”。还有一个领域叫做“演奏生成(Performance Generation)”。我不是这方面的研究者,就不说一些言之凿凿的话。但是,情感并非不可表达、不可描述之物。从本世纪初的研究来看,情感可以用V-A坐标进行分类,从而将情感映射到低维空间中;情感也可以通过统计的方式,映射到一个高维空间中进行拟合。只要是关于经验的知识,我们都可以用统计学习的方法解决;只要是关于乐理的知识,我们都可以设计归纳偏置的方法解决。在巨大的参数量和人类的模型设计面前,正确建模情感并非镜中花、水中月,而是有迹可循的规律。
尽管这个领域还有很多未解决的工作,但本领域也并没有处于刀耕火耨的原始时代,顺利通过音乐图灵测试的模型已经不少了,一般人对音乐的感知正在被机器所覆盖,到达不了机器的能力边界。我的同行们普遍受到了正统的音乐训练,能分辨出绝大多数的人工音乐。但是,现代的音乐生成模型,绝不是一句“没有灵魂”就能概括的。换句话说,音乐基础不够扎实的一般人,面对真假难辨的人工音乐,凭什么能说出“没有灵魂”的评价?我在此要问问大家:
听完下面的demo之后,我们是不是该放下傲慢,问问自己是否低估了整个领域付出的努力?
计算机音乐领域,是一个广阔的领域。其主要的研究方向包括音乐识别、音乐信息处理、音乐旋律与节奏分析、音频音乐检索、音频数据挖掘与推荐、音乐情感计算、音乐结构分析、算法作曲、自动编曲、说话人识别、语音增强、音频信息安全等。2017年,英伟达公司发布了AIVA人工智能作曲模型,随后迅速得到商用,广泛用于网络视频的自动配乐。也正是这时候,音乐人工智能领域进入深度学习时代,深度学习算法成为本领域在国际工业界中的核心技术,被索尼、Spotify、苹果等公司使用在其音乐产品上;字节跳动招募了大量相关人才,研发了火山小视频和抖音应用的音乐推荐、音乐搜索算法,得到广泛使用;腾讯音乐部门将音乐信息检索的算法应用在社交互动领域,使得用户获得更好的音乐社交体验。
其中最引人注目的topic之一,就是自动作曲。随着这波深度学习大潮,自动作曲技术也取得了很大的进展。之前的回答都比较老了,我从2020年年初这个时间节点开始讲吧。
本文的讲述脉络主要参考Jean-Pierre Briot教授写的综述《From Artificial Neural Networks to Deep Learning for Music Generation》(2020)。大约40%的观点转述于这篇文章。除此之外,还参考了:
《Deep learning techniques for music generation--a survey》,也是Briot教授在2017年写的综述。Gus Xia老师的计算机音乐中文tutorial:youtube.com/watch?v=dPeh3XVlmlE成电微软学生俱乐部,2020年学术沙龙的报告:bilibili.com/video/BV18E411V768计算机音乐最知名的国际顶会ISMIR近年的paper:ismir.net/
2023年是AIGC大火的年份,答主已经被冲晕了……
值得关注的两篇工作是diffusion方面的Riffusion,以及Google的MusicLM。这两篇工作比较有代表性。

2022年推荐一篇综述,算是比较全面的了:
Ji, Shulei, Jing Luo和Xinyu Yang. 《A Comprehensive Survey on Deep Music Generation: Multi-Level Representations, Algorithms, Evaluations, and Future Directions》. arXiv, 2020年11月13日.
人工智能音乐生成的一些sample:
NVIDIA的AIVA音乐样例(2016年,交响乐),时长一小时:
Google Magenta的MusicVAE模型样例(2018年,单音旋律),需要科学上网:
University of Rochester今年的一个算法样例(2019年,交响乐),需要科学上网:
OpenAI的Jukebo模型,给定语言模型生成的歌词和一些metadata,生成以假乱真的英文流行歌(2020年),需要科学上网。
音乐生成的起源
早期,莫扎特曾经创作过一首《骰子音乐》,通过丢骰子的方法自动选择小节组合:组合出来的完整音乐仍然悦耳,但是创作的过程带有一定的随机性。一个在线的demo如下:
1950年代,第一批计算机发明后,出现了第一批计算机音乐。最早的音乐构建了一个马尔科夫过程,使用随机模型进行生成,辅以rule-based的方法挑选符合要求的结果。
当然这类方法生成的音乐质量不高。随着机器学习的发展,算法应该从音乐材料中自动地学习出一些规律,得到自然的音乐。
2. 两种音乐生成
人类大致有两种方法参与自动音乐生成:
目前大部分的算法都属于第一类方法。第二种方法在很多情况下是第一种方法的组合和变体。
3. 一个例子
2019年3月21日,Google Magenta组贡献了一个交互式算法demo,称为Bach Doodle,通过学习J. S. Bach的四重奏,算法可以由用户指定第一声部,然后自动计算给出剩余的三个声部。
(虽然很难听,但是Magenta在computer music领域黑不动)

Bach Doodle
我们以这个算法的雏形和前身“MiniBach”算法开始。
To specify the problem, 我们形式化决定算法仅生成四个小节的音乐。
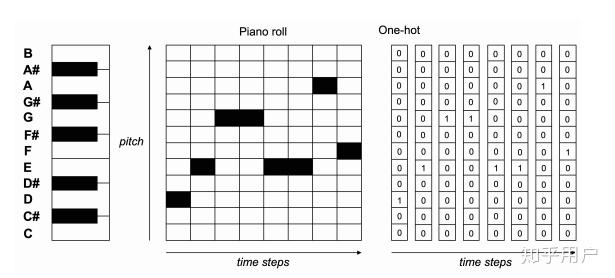
如何将音乐转换为符号表示,其实有很多种方法。被公认的主流方法之一是piano-roll及其变体。midi可以表示128个不同的音高,将129指定为rest,130指定为sustain(持续),则音乐可以用一个130*N的矩阵表示。N取决于分辨率和音乐实际长度。主流设置是将16分音符作为最小的分辨率,那么一个4/4拍的两小节音乐可以被表示为130*32的矩阵。
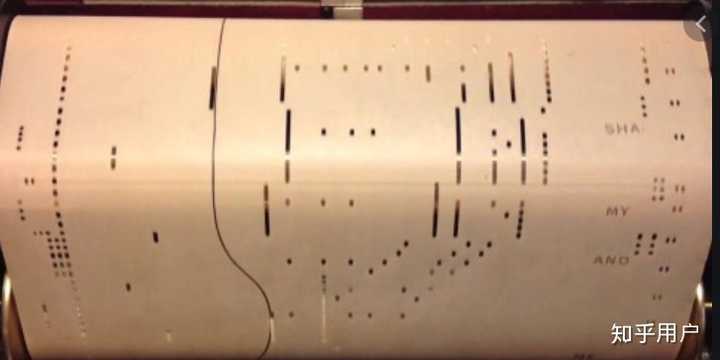
piano roll的起源是匀速运动的打孔纸带
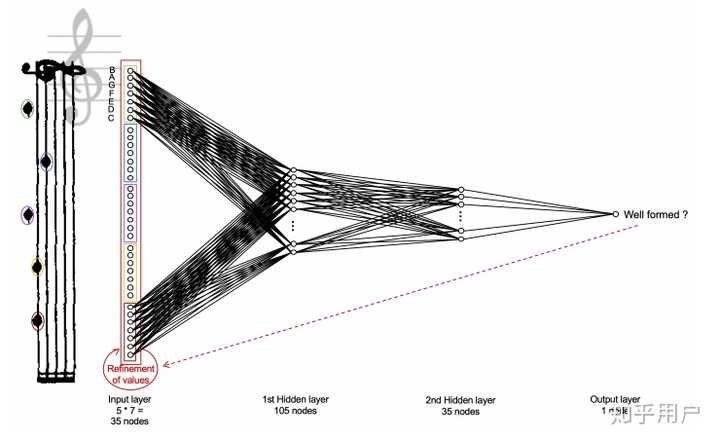
然而minibach作为早期模型,没有采用成熟的表示法,而是将21个音高*16个step*4个小节=1344,一共1344个node,使用了一个多分类器进行学习:
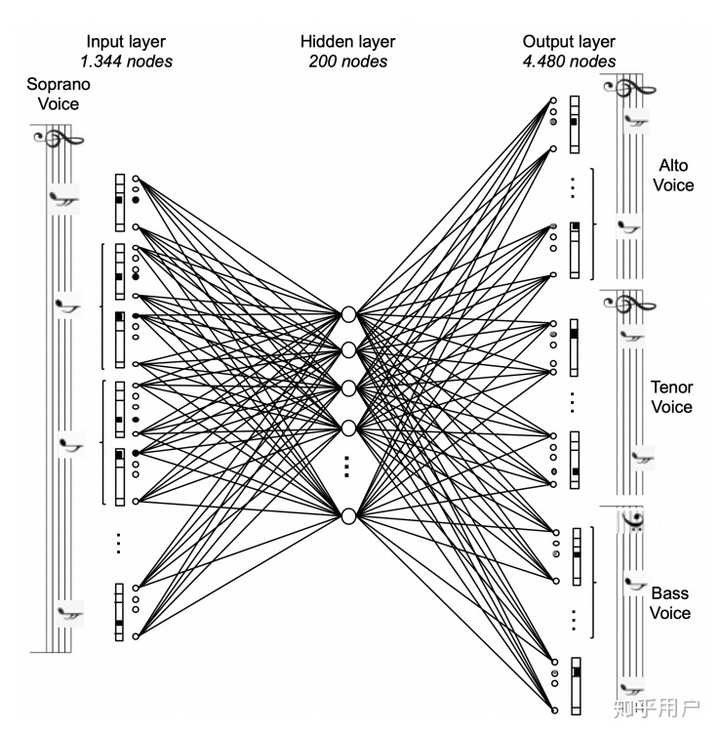
minibach
4. 音乐人工智能的先驱者们
请容许我跳过传统机器学习算法做计算机音乐生成的相关介绍,直接进入神经网络相关的模型介绍——这一波星星之火随着深度学习的浪潮而兴起。
下面介绍两类先驱模型,他们给现在的算法带来了很多启发。
首先是Todd的时间窗口-条件循环结构。
Todd的目标是以迭代的方式产生单音旋律(monophoic melody)。他的第一个设计是time-window结构,通过滑窗的方法,逐段地反复地进行旋律生成,上一段的输出作为下一段的输入。这是一个非常直接且朴素的想法。注意,这个idea是在1989年产生的,距离LSTM的正式诞生还有26年。
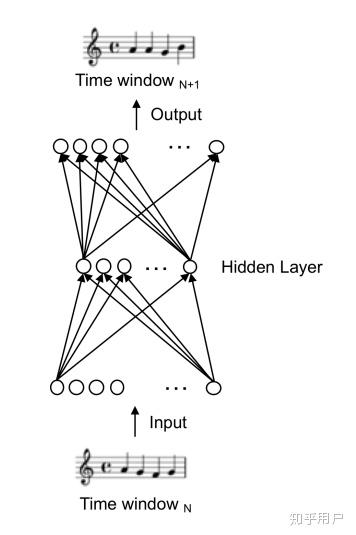
Todd的Time Windows结构
他还设计了Sequential结构,输入层分为两部分,分别是context和plan。context是生成的历史旋律,而plan是预先设置的需要网络学习的特定旋律的名字。
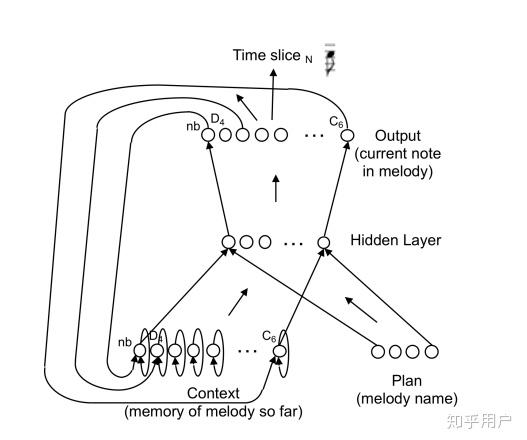
Todd的循环结构
Todd的这个模型影响深远,甚至可以看作是conditional network结构的先驱。
Todd后续还陆续提及了一些想法,希望得到解决,他们包括:
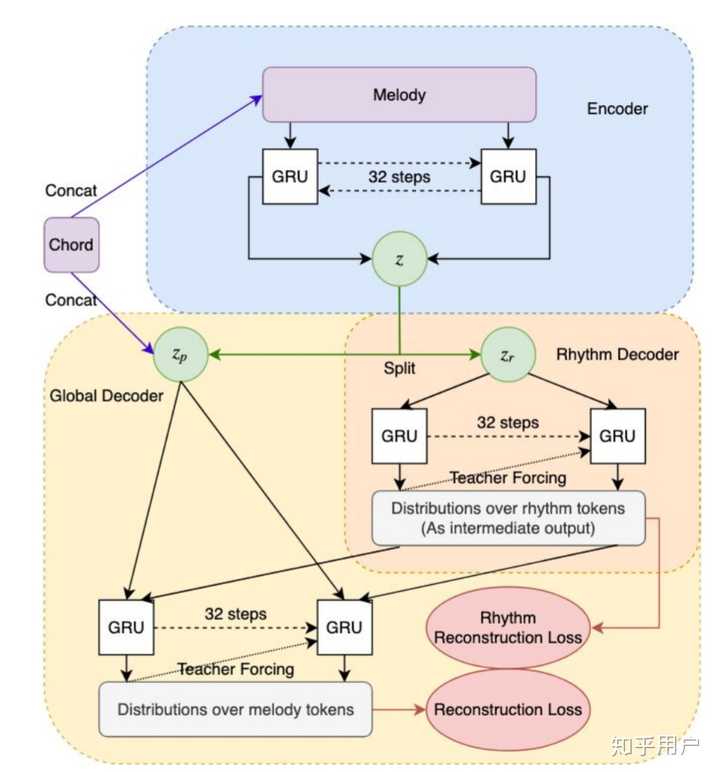
MusicVAE
ClockRNN
第二个提到的人是Lewis,他提出了基于refinement的方法(Creation by Refinement, CBR),提出通过梯度下降的方式训练模型。Lewis人工构建了正确的和没那么正确的旋律,通过我们现在熟知的方法进行网络训练。
Lewis的算法可以是看作最大化一些目标属性,以控制生成模型的各类方法的前身。现代的诸多算法都使用了类似的机制,如DeepHear最大化与给定目标的相似度,DeepDream最大限度地激活特定单元,等等。
Lewis的模型
最有趣的事实是,这个网络使用梯度下降和反向传播机制进行训练的,而那时是1988年。
此外,Lewis颇有创意地提出了一种attention机制和一种hierarchy方法。这个方法简单来说,有点类似于一类形式语法规则,如ABC变为AxByC,在不改变现有token的情况下,使用attention地方式选择位置,然后进行拓展。
与综述一样,我们从下面五个方向展开介绍:
要注意上面五个方法并不是正交的,
那么我们首先来聊聊音乐的表示法。音乐主要以两种形式表示:audio和symbolic。所以前几年相关的基础研究,有的会说自己是“symbolic domain music generation”,最近见得少了。
而文本格式中最被广泛使用的为ABC notation。现在还有活跃的社区在收集ABC标注的数据集:abcnotation.com/
也有相关的网站提供了ABC格式在线渲染乐谱的demo,有兴趣的话可以访问这个网站,体验一下ABC notation和乐谱的对应关系:ldzhangyx.github.io/abc/
在一些格式中,模型会遇到编码问题。比如说音高pitch,既可以用一个实数表示,也可以用一个one-hot向量表示,甚至可以通过二进制来表示。目前one-hot是最为广泛的采用方法。
之后我们来聊一些基本的模型。这些模型包括:
之后是一些复合架构。复合的方法可以分为下面几种:
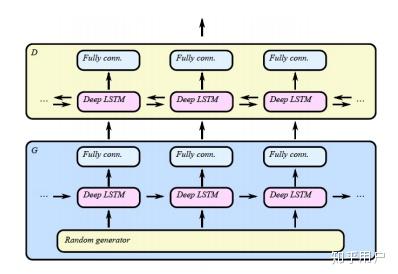
C-RNN-GAN的结构
下图是流行模型的分类归属:
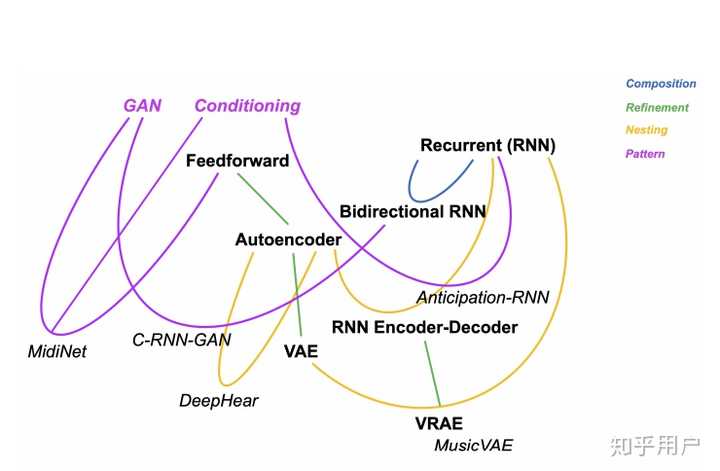
我们再讨论一些改进的架构。
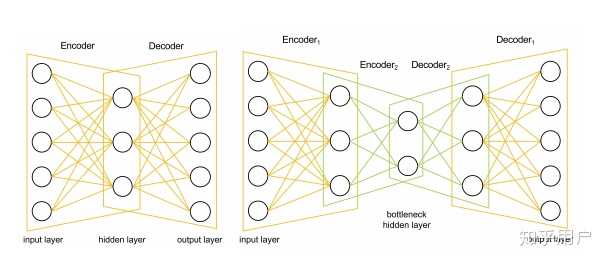
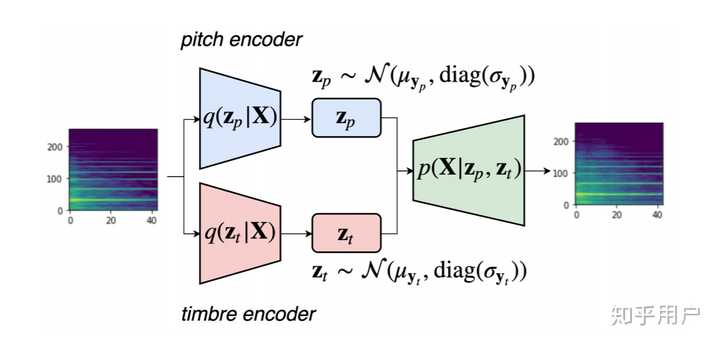
有工作试图将latent Z解耦,利用多个encoder和decoder进行表征学习的工作,如ISMIR 2019的音色分离模型:
事实上得到latent Z之后,可以通过多种方法对Z进行decoding,得到音乐。比如说sample一个符合原分布的向量,再交给Decoder进行VAE的解码工作。当然,插值等方法也是可以使用的。
目前一个研究热点问题是对VAE中的latent Z进行解释、分离,以达到表示学习的目的。如ISMIR 2019上一篇音乐节奏风格迁移的文章,就是将latent Z的不同部分分别约束,强制latent vector包含特定的含义。
简单的说了一下VAE之后我们再讨论GAN模型。GAN模型近年来远没有VAE模型多见,而更多地用作弱监督环境下提升质量的方法。前几年的MidiNet就是GAN模型:
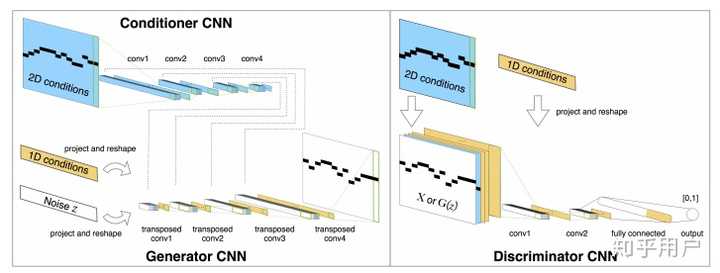
MidiNet
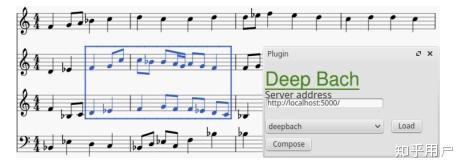
正如我之前提到的,对网络的中间变量进行采样,然后对生成的结果做迭代的细化,也是生成的一个策略。DeepBach采用了类似的策略:
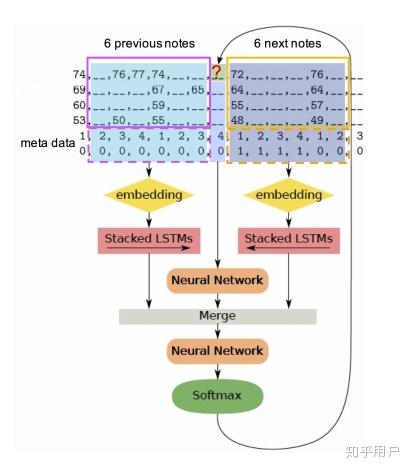
在实际使用中,DeepBach可以指定重新生成音乐的任意部分,无需重新生成整个内容:
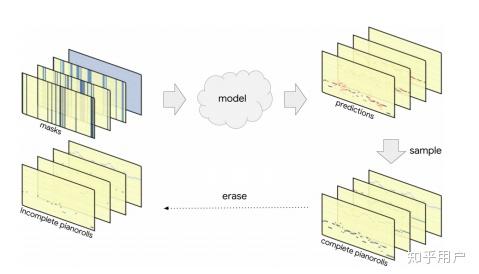
无独有偶,Bach Doodle的原文CocoNet,也采用了相似的方法。网络通过反复擦除不同地方的结果,让网络进行补完,之后采样,再补完,迭代地细化结果:
最后简单介绍几个最新的模型、算法。
Learning to Traverse Latent Spaces for Musical Score Inpainting, ISMIR 2019
Ashis Pati; Alexander Lerch; Gaëtan Hadjeres
"Recurrent Neural Networks can be trained using latent embeddings of a Variational Auto-Encoder-based model to to perform interactive music generation tasks such as inpainting."
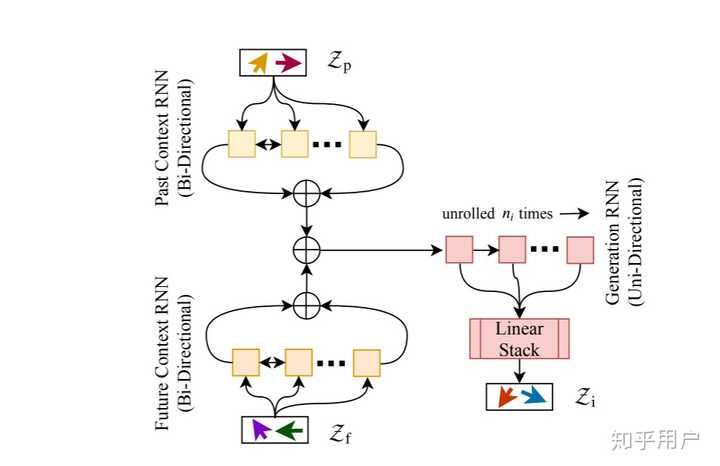
LatentRNN
这篇文章提出了音乐补完的任务,通过对上下文的latent vector进行分析和整理,模型可以实现任意位置的局部音乐生成。
RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning, AAAI 2020
N Jiang, S Jin, Z Duan, C Zhang
arXiv preprint arXiv:2002.03082
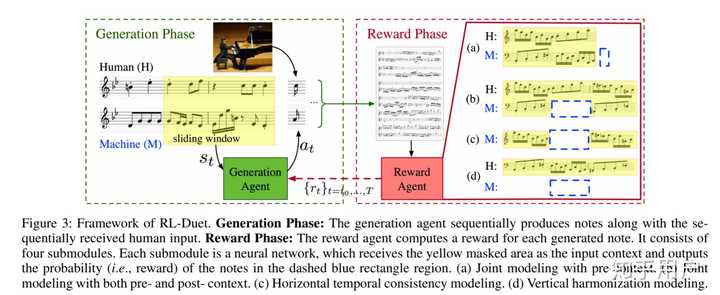
RL-Duet
这篇文章使用深度强化学习算法,做到了实时交互的人机二重奏。
Pop Music Transformer: Generating Music with Rhythm and Harmony
YS Huang, YH Yang
arXiv preprint arXiv:2002.00212
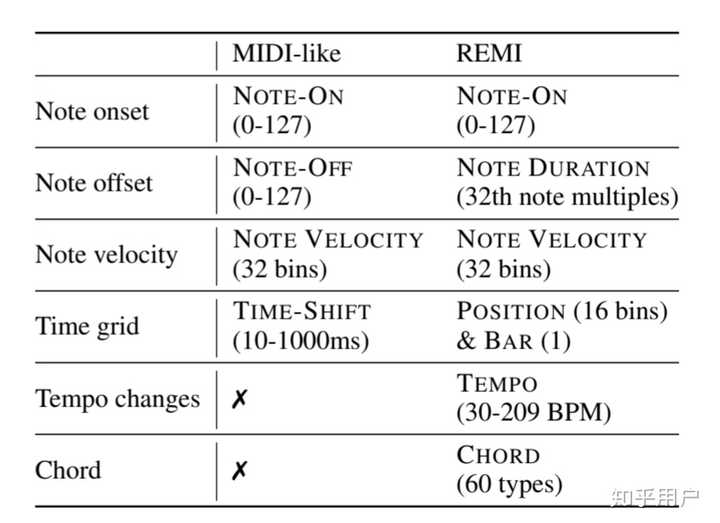
这篇文章使用了音乐的改进表示法,使得Transformer音乐生成模型的生成质量大为提升。
Jukebox: A Generative Model for Music
Prafulla Dhariwal * 1 Heewoo Jun * 1 Christine Payne * 1 Jong Wook Kim 1 Alec Radford 1 Ilya Sutskever 1
cdn.openai.com/papers/jukebox.pdf
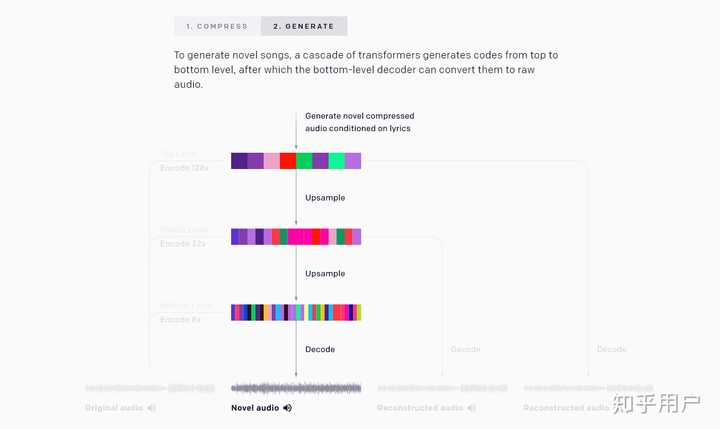
这篇文章使用多尺度VQ-VAE将原始音频压缩为离散代码,并使用自回归Tranformer对其进行建模,从而解决了原始音频的长期问题。 结果表明,这个组合的模型在规模上可以生成高保真和多样化的歌曲,并具有长达数分钟的连贯性。 模型可以根据艺术家和流派来控制音乐和人声风格,并根据未对齐的歌词来使音乐更加可控。
最后闲聊一些别的。音乐生成领域非常广阔,从计算机音乐顶会ISMIR每年CfP时的说明就可以看出来,有很多值得研究的主题。
在这些主题中,纯粹的音乐生成其实并不是最热门的方向。在音乐信息检索、音乐转录、哼唱识别、音乐学研究等领域,也有无数学者孜孜不倦地努力着。

此外,计算机音乐也与NLP、数据挖掘等领域紧密相关。KDD、ICML等会议都曾出现过相关论文和workshop。国际上研究这个领域的实验室也不少:smcnetwork.org/centers.html
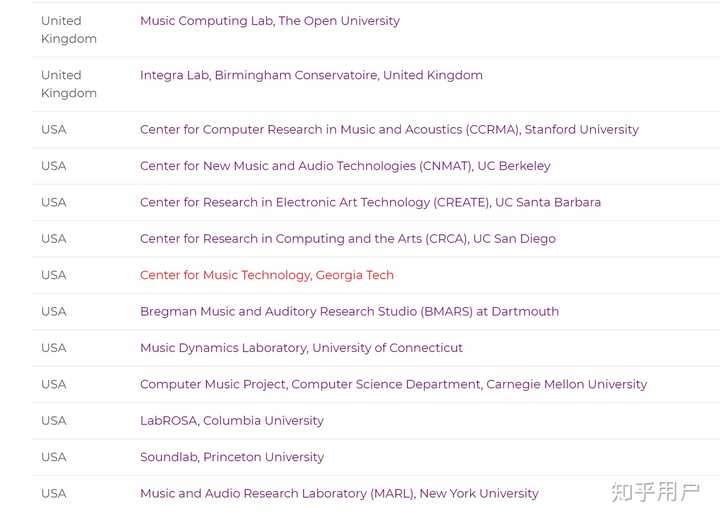
部分截图
欧洲比较著名的研究机构,包括Queen Mary的C4DM,规模和整体科研实力都是在欧洲数一数二的:
法国的IRCAM:

西班牙的UPF-MTG:
北美斯坦福的CCRMA:

纽约大学的MARL:
麦吉尔大学的CIRMMT:
亚洲新加坡国立大学:

日本京都大学:
遗憾的是,我们国家在计算机音乐领域还远没有发展起来。
中国近年来成立了我们自己的社区,有了自己的会议:
与我比较熟的同行们,主要来自下面的实验室:
复旦大学李伟老师的实验室:

上海纽约大学夏光宇老师的实验室:
至于工业界,主要是腾讯的QQ音乐:

字节跳动的抖音:

可以明显地感觉到,国内和国外,不管是工业界还是学术界,都有着数量上的明显差距。国内的计算机音乐方兴未艾,这对所有从业者来说,既是挑战,也是机会。








